Abstract
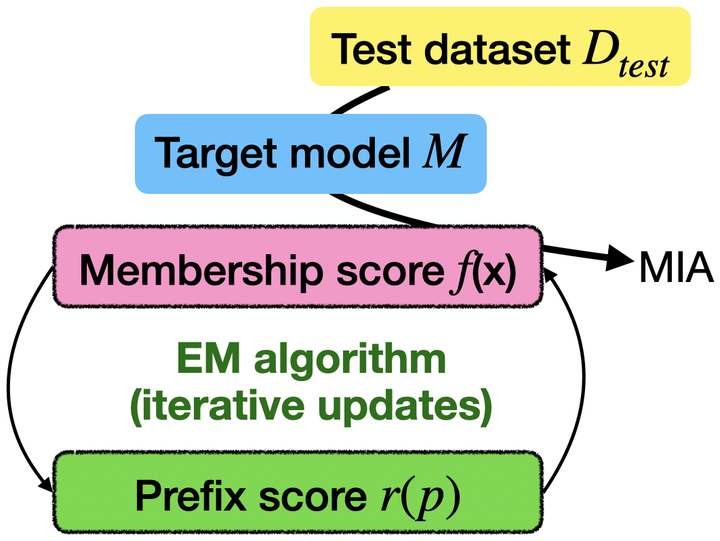
The advancement of large language models has grown parallel to the opacity of their training data. Membership inference attacks (MIAs) aim to determine whether specific data was used to train a model. They offer valuable insights into detecting data contamination and ensuring compliance with privacy and copyright standards. However, MIA for LLMs is challenging due to the massive scale of training data and the inherent ambiguity of membership in texts. Moreover, creating realistic MIA evaluation benchmarks is difficult as training and test data distributions are often unknown. We introduce EM-MIA, a novel membership inference method that iteratively refines membership scores and prefix scores via an expectation-maximization algorithm. Our approach leverages the observation that these scores can improve each other: membership scores help identify effective prefixes for detecting training data, while prefix scores help determine membership. As a result, EM-MIA achieves state-of-the-art results on WikiMIA. To enable comprehensive evaluation, we introduce OLMoMIA, a benchmark built from OLMo resources, which allows controlling task difficulty through varying degrees of overlap between training and test data distributions. Our experiments demonstrate EM-MIA is robust across different scenarios while also revealing fundamental limitations of current MIA approaches when member and non-member distributions are nearly identical.