KnapSpec: Self-Speculative Decoding via Adaptive Layer Selection as a Knapsack Problem
Abstract
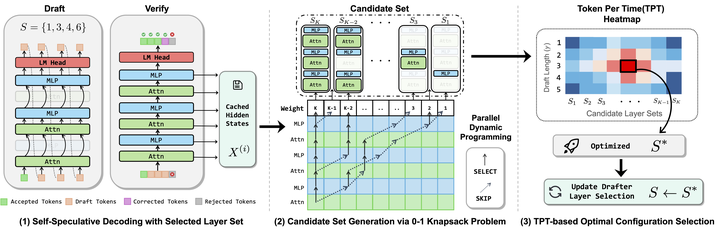
Self-speculative decoding (SSD) accelerates LLM inference by skipping layers to create an efficient draft model, yet existing methods often rely on static heuristics that ignore the dynamic computational overhead of attention in long-context scenarios. We propose KnapSpec, a training-free framework that reformulates draft model selection as a knapsack problem to maximize tokens-per-time throughput. By decoupling Attention and MLP layers and modeling their hardware-specific latencies as functions of context length, KnapSpec adaptively identifies optimal draft configurations on the fly via a parallel dynamic programming algorithm. Furthermore, we provide the first rigorous theoretical analysis establishing cosine similarity between hidden states as a mathematically sound proxy for the token acceptance rate. This foundation allows our method to maintain high drafting faithfulness while navigating the shifting bottlenecks of real-world hardware. Our experiments on Qwen3 and Llama3 demonstrate that KnapSpec consistently outperforms state-of-the-art SSD baselines, achieving up to 1.47x wall-clock speedup across various benchmarks. Our plug-and-play approach ensures high-speed inference for long sequences without requiring additional training or compromising the target model’s output distribution.