Abstract
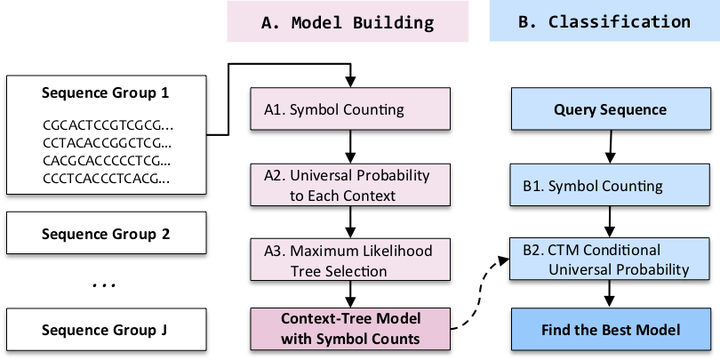
Motivated by the need for fast and accurate classification of unlabeled nucleotide sequences on a large scale, we developed NASCUP, a new classification method that captures statistical structures of nucleotide sequences by compact context-tree models and universal probability from information theory. NASCUP achieved BLAST-like classification accuracy consistently for several large-scale databases in orders-of-magnitude reduced runtime, and was applied to other bioinformatics tasks such as outlier detection and synthetic sequence generation.
Type