ST-BERT: Cross-modal Language Model Pre-training For End-to-end Spoken Language Understanding
Abstract
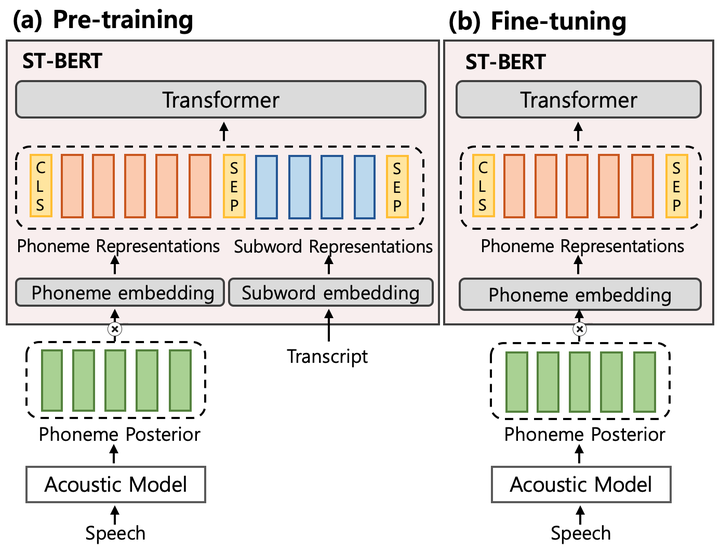
Language model pre-training has shown promising results in various downstream tasks. In this context, we introduce a cross-modal pre-trained language model, called Speech-Text BERT (ST-BERT), to tackle end-to-end spoken language understanding (E2E SLU) tasks. Taking phoneme posterior and subword-level text as an input, ST-BERT learns a contextualized cross-modal alignment via our two proposed pre-training tasks: Cross-modal Masked Language Modeling (CM-MLM) and Cross-modal Conditioned Language Modeling (CM-CLM). Experimental results on three benchmarks present that our approach is effective for various SLU datasets and shows a surprisingly marginal performance degradation even when 1% of the training data are available. Also, our method shows further SLU performance gain via domain-adaptive pre-training with domain-specific speech-text pair data.