Two-stage Textual Knowledge Distillation for End-to-End Spoken Language Understanding
Abstract
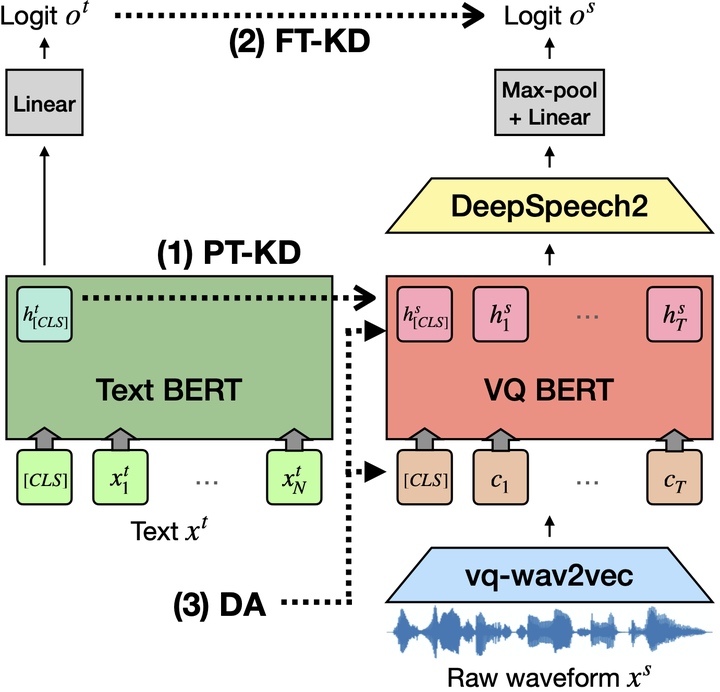
End-to-end approaches open a new way for more accurate and efficient spoken language understanding (SLU) systems by alleviating the drawbacks of traditional pipeline systems. Previous works exploit textual information for an SLU model via pre-training with automatic speech recognition or fine-tuning with knowledge distillation. To utilize textual information more effectively, this work proposes a two-stage textual knowledge distillation method that matches utterance-level representations and predicted logits of two modalities during pre-training and fine-tuning, sequentially. We use vq-wav2vec BERT as a speech encoder because it captures general and rich features. Furthermore, we improve the performance, especially in a low-resource scenario, with data augmentation methods by randomly masking spans of discrete audio tokens and contextualized hidden representations. Consequently, we push the state-of-the-art on the Fluent Speech Commands, achieving 99.7% test accuracy in the full dataset setting and 99.5% in the 10% subset setting. Throughout the ablation studies, we empirically verify that all used methods are crucial to the final performance, providing the best practice for spoken language understanding. Code to reproduce our results will be available upon publication.